Using time intelligence
is one of the great features of using SSAS. I often find that it’s useful to use data
periods with dashboard objects instead of simple data ranges. For example, if
you want to filter the data by the last 7 days, you often have to specific the
current date and the last seven days. This would be try as well for current
month. To simplify this process, I would suggest creating a date period for
common date selections. For the date
period as follows...
- Current Month
- Last Two Months
- Last Three Months
- Last Six Months
- All Periods
You would
first simply create a Calculated Table
in your Tabular Model with the following DAX Query:
= UNION (
ADDCOLUMNS(
SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal Week'[FiscalDate], EOMONTH(TODAY(),-1)+1,TODAY()) ), 'Fiscal
Week'[FiscalDate]),"Period","Current Month") ,
ADDCOLUMNS(
SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal Week'[FiscalDate], EOMONTH(TODAY(),-2)+1 ,TODAY()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last Two Months") ,
ADDCOLUMNS(
SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal Week'[FiscalDate], EOMONTH(TODAY(),-3)+1 ,TODAY()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last Three Months") ,
ADDCOLUMNS(
SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal Week'[FiscalDate], EOMONTH(TODAY(),-6)+1 ,TODAY()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last Six Months") ,
ADDCOLUMNS(
SUMMARIZE( CALCULATETABLE('Fiscal Week'), 'Fiscal
Week'[FiscalDate]),"Period","Overall") )
In this
example, we could use data periods by days as well…
- Last 7 Days
- Last 14 days
- Last 30 days
- Last 90 days
- All Periods
= UNION (
ADDCOLUMNS( SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal
Week'[FiscalDate],today()-07+1,today()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last 07 Days") ,
ADDCOLUMNS( SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal
Week'[FiscalDate],today()-14+1,today()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last 14 Days") ,
ADDCOLUMNS( SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal
Week'[FiscalDate],today()-30+1,today()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last 30 Days") ,
ADDCOLUMNS( SUMMARIZE( CALCULATETABLE('Fiscal Week' ,
DATESBETWEEN('Fiscal
Week'[FiscalDate],today()-90+1,today()) ), 'Fiscal
Week'[FiscalDate]),"Period","Last 90 Days") ,
ADDCOLUMNS( SUMMARIZE( CALCULATETABLE('Fiscal Week'), 'Fiscal Week'[FiscalDate]),"Period","Overall") )
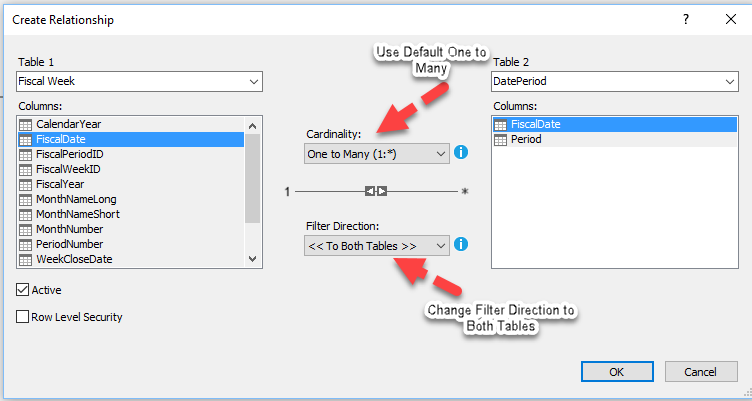
Once you’ve
created the Calculated Table, you must add a relationship to the Date Table in
your model. In this example, we create the relationship with the Date Period
calculated table in the a Table called Fiscal Week. We simple use the default Cardinality: One to Many for the Filter
Direction, we use Both Tables.

Select OK to
save and after deploying the model you should be able to filter by periods.





